AI基础
基础概念
模型:是基于深度学习技术训练的具有大规模参数的模型;
数据集:是用来训练大语言模型的数据;
预训练模型:是指在大规模数据集上进行了预先训练的模型;
模型微调:是指在预训练模型的基础上,使用特定任务的数据对模型进行进一步训练以适特定任务的过程;
模型微调
有两种常见的微调方法:
1> LoRA微调:是一种轻量级的微调方法,只对某些层进行微调,需要的计算资源和时间较少,同时也能降低了过拟合的风险;适用于计算资源有限、数据集较小的情况;
2> 全量参数微调:是指对整个大语言模型的所有参数进行微调,需要更多的计算资源和时间,容易出现过拟合的情况;适用于数据集较大且目标任务与预训练任务有较大差异的情况。
相关技术
Hugging Face是AI领域的GitHub,目前已托管了20多万个模型;
Transformer是Hugging Facer提供的一个机器学习工具,其提供了数以千计的预训练模型,相当于是一个预训练模型的工具包;支持 100 多种语言的文本、音频、语言、图像处理;
LangChain是一个用于构建 LLM(大型语言模型) 支持的应用程序的开源框架,它能够将多个模型或组件组合在一起,组成一个单一的、连贯的应用;
TensorFlow是用于机器学习和深度学习的开源软件库,提供了用于构建和训练神经网络的工具和 API,由 Google 开发,使用静态计算图来表示神经网络;
PyTorch是用于机器学习和深度学习的开源软件库,与 TensorFlow 作用相同,但由 Facebook 开发,使用动态计算图来表示神经网络;
Transformer
1.0> Pipeline是Transformer中的一个调用模型的工具,它将调用模型的复杂代码抽象成了简单的API;提供了对各种任务进行处理的模型,如下图中的自然语言、音频、图像等处理;
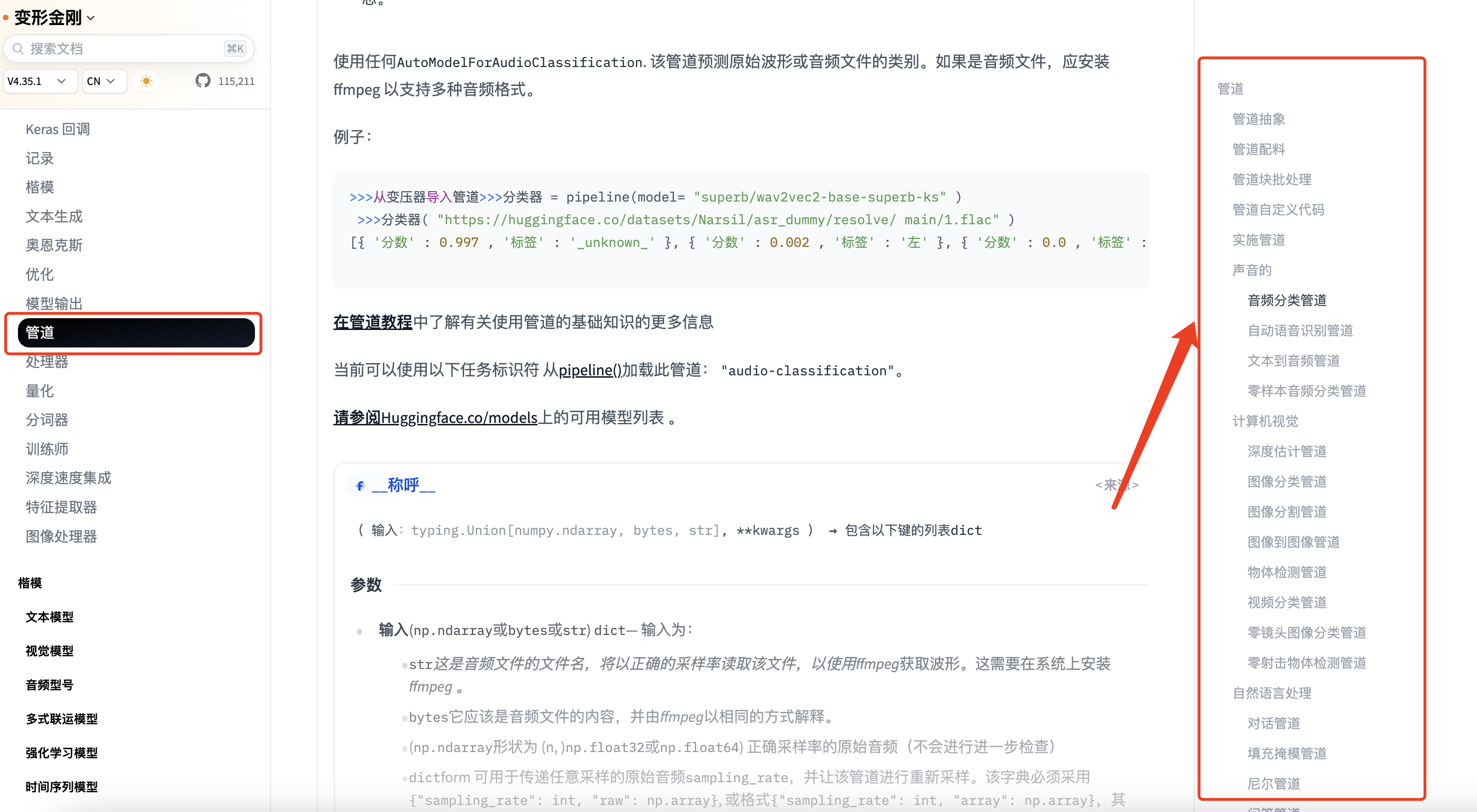
2.0> 任务模型库
Pipeliner执行任务时所有调用的所有模型全在这里:https://huggingface.co/tasks,这个页面中列出了各类别任务下的所有模型;如下图:
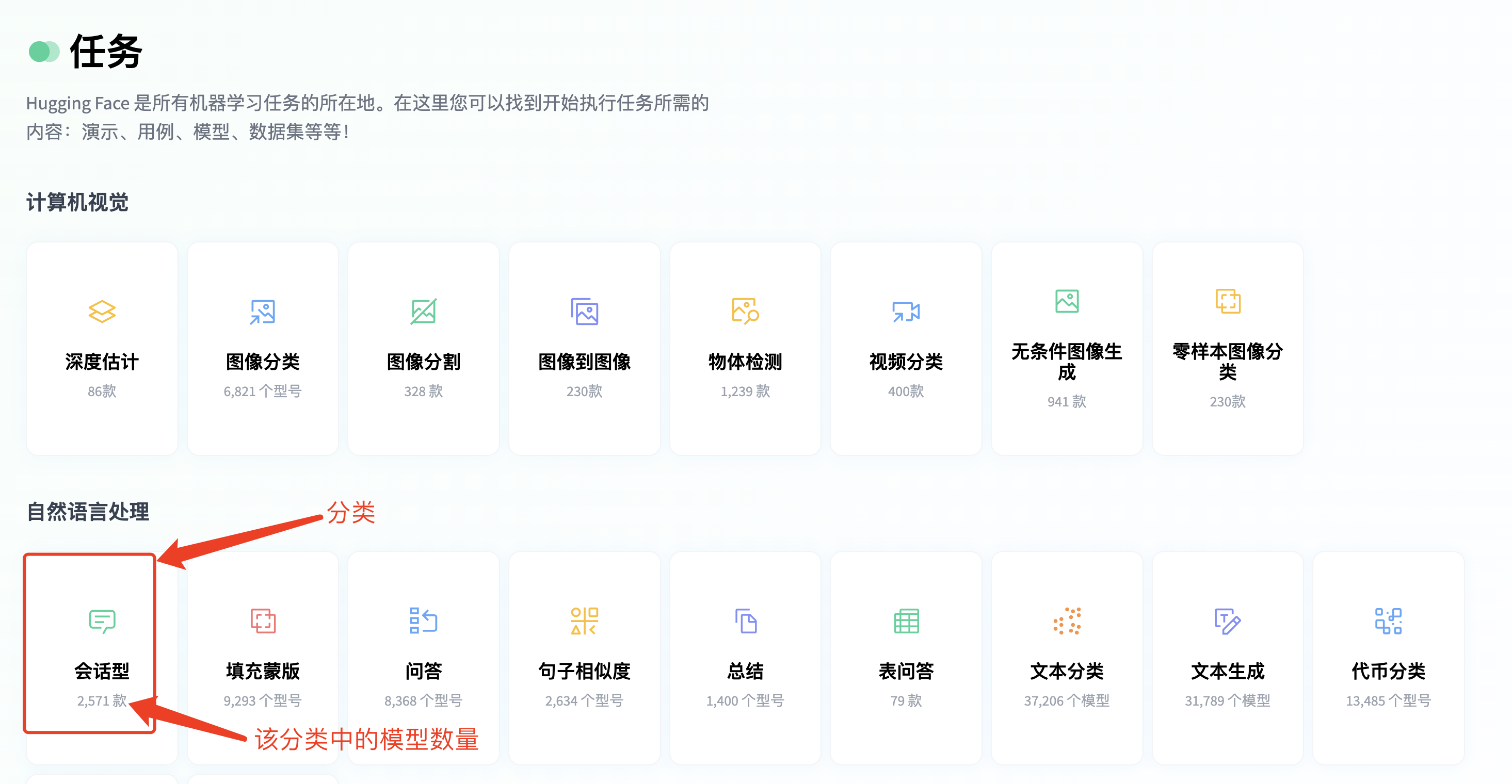
使用Pipeliner时,如果只声明了任务分类,而未定义模型,则Pipeliner在执行任务时,会自动在指定的任务分类中选择一个模型;
Azure生成人声较好
# 更新pip到最新版
pip install pip